April 29, 2026
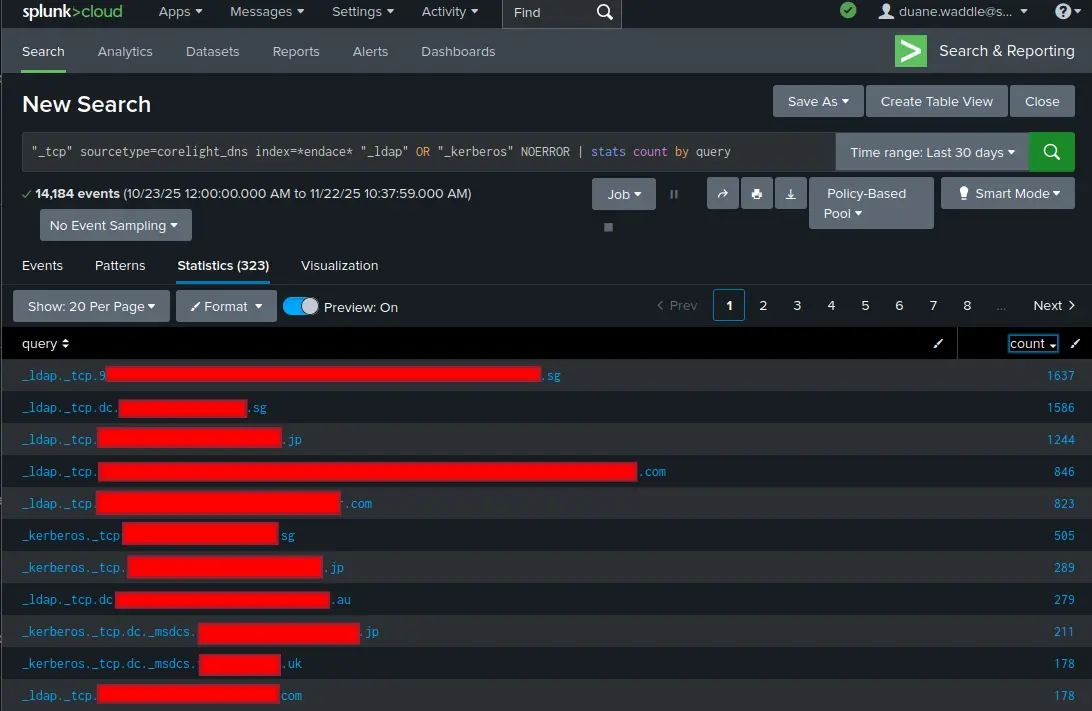
The Cisco article argues that data optimization in Splunk-based security environments should not be treated merely as a cost-cutting exercise. Jeff Yeo’s central point is that poorly designed optimization can weaken detection fidelity, disrupt correlation searches in Splunk Enterprise Security, reduce the effectiveness of risk-based alerting, and slow investigations. He says the most common mistake is making retention and index-design decisions before detection engineering is mature, which can create blind spots that only become visible after coverage has already been lost. To avoid that, the piece urges security teams to ask whether a data source supports correlation searches, risk scoring, suppression logic, or compliance reporting before reducing ingest or retention.
The article then presents a detection-driven framework for assigning data to Splunk’s Active, Selective, and Archive tiers based on analytic value rather than storage economics alone. Active data should remain high-performance and detection-critical; Selective data can support deeper investigations and historical hunting, often with SmartStore, but only if cache sizing and search behavior are tested under realistic incident-response load; and Archive data should still have proven retrieval procedures rather than functioning as de facto deletion. Yeo also highlights several “blind spots,” including broken Common Information Model compliance, weakened machine-learning baselines, over-filtering at ingest, and search-head concurrency problems. His conclusion is that optimization success should be measured not by cost per gigabyte, but by operational outcomes such as stable detection coverage, investigation completeness, search latency, and improved mean time to respond.
Source: https://blogs.cisco.com/security/data-optimization-in-security-splunk-architects-perspective















.webp)


